HEC-DSS File and HEC-DSSVue – Time Series and Paired Data
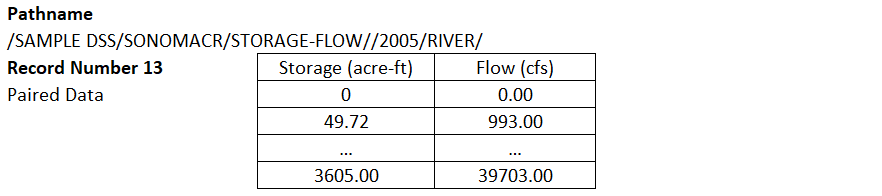
HEC-DSS, USACE Hydrologic Engineering Center Data Storage System, is a type of database system to store data primarily for hydrologic and hydraulic modeling (*.dss file). HEC-DSSVue is a tool to view, edit, and visualize a HEC-DSS file. Unlike other commercial or open source databases, HEC-DSS is not a relational database: HEC-DSS uses blocks (records) to store data within a HEC-DSS file and each HEC-DSS file can have numerous blocks (records), for example, 1. time series data of river flow rate from 27 December 2005, 12:00 to 29 December 2005, 08:30 is a record (Figure 1), or 2. a paired data to define a river’s storage-flow relationship is also a record (Figure 2). Gridded data can also be stored in a HEC-DSS file which is covered by another post.

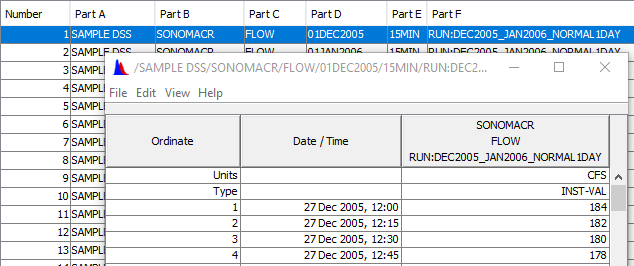
A record in HEC-DSS (download the sample dss file here) is identified or indexed by a “pathname” and a list of all the pathnames in a HEC-DSS is a catalog (Figure 3). A pathname consists of six parts which are separated by a slash “/”. A typical pathname looks like: /A/B/C/D/E/F/ and some parts can be null: ///C/D/E//.

Pathnames for different types of data have different naming conventions.
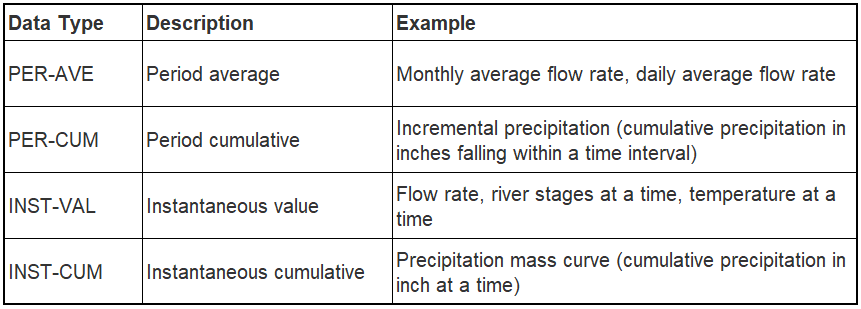
- Time Series Data (regular only, irregular time series is not covered by this post): Four types of time series data primarily for H&H modeling purpose in HEC-DSS are summarized in Table 1.
The six parts of a time series data pathname are explained below:
- Part A of time series – group: can be a watershed name, project name, a river or basin name, or null;
- Part B of time series – location: basic location identifier, such as a USGS gage ID, a junction ID, an outlet name, or null;
- Part C of time series – data parameter: such as FLOW, ELEV, PRECIP-INC, STAGE, STORAGE, normally can not be null;
- Part D of time series – identifier for a time series start date, for example, 01JAN2005, normally can not be null;
- Part E of time series – identifier for time interval, for example, 15MIN, normally can not be null;
- Part F of time series – descriptor: any additional information can be typed in, can be null.
Regular time series data is stored in “standard size” blocks whose length depends upon the time interval of the data. For example, monthly time interval data are stored in blocks of one decade (120 values/block), 15-min, hourly, or daily time interval data are stored in blocks of one month, and 5 sec, 10sec, 5 min or 10 min time interval values are stored in blocks of one day. The starting and ending times of a block correspond to standard calendar conventions. For example, for period average monthly flow data in the 2010’s, Part D of the pathname would be 01JAN2010, regardless of when the first valid data occurred (e.g., it could start in March 2015). For Record Number 1 in Figure 1, even though the first valid data is at 12:00 on 27 Dec 2005 (Figure 4), the Part D of its pathname is still 01DEC2005 since a 15-min interval time series data is stored in blocks of one month and the Part D starts with the first day of the month.
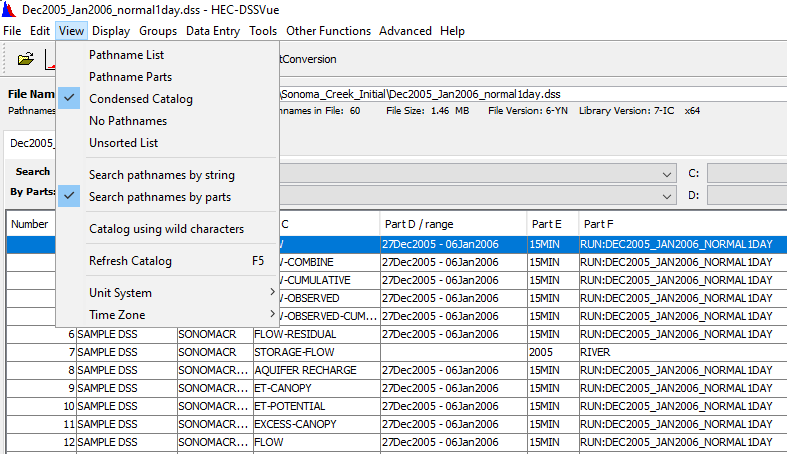
For time series data, its pathname can be condensed by switching to “Condensed Catalog” view of pathnames (Figure 5). Part D of the condensed pathname will change to time range of the entire data set for the time series.
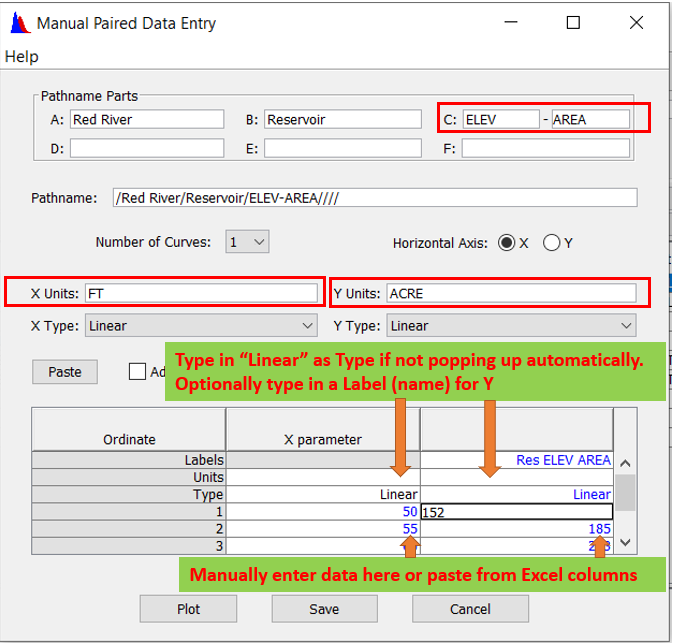
- Paired Data is a group of data to represent the relationship of two variable (x-y) or more variable (such as x-y1, y2,…). A paired data pathname also consists of six parts but they have different meanings from that of time series data.
- Part A of paired data – group: can be a watershed or basin name, project name, a city, county, or state name, or null;
- Part B of paired data – location: basic location identifier, such as a station or gage ID, a junction ID, a reservoir or river name, or null;
- Part C of paired data – data parameter with two names separated by a hyphen: such as ELEV-FLOW, STORAGE-FLOW, ELEV-STORAGE, and ELEV-AREA, normally can not be null. The first part is independent variable and the second part is dependent variable;
- Part D of paired data – descriptor to provide further descriptions of the data, usually is null for paired data;
- Part E of paired data – identifier for time: only used if the paired data is representative of a specific point in time usually is null;
- Part F of paired data – labeling descriptor: sometimes used as part of a label of paired data.
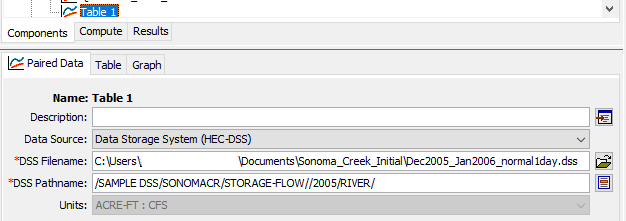
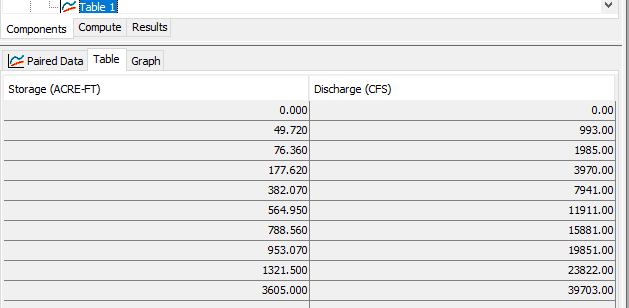
Time series data and paired data stored in HEC-DSS can be retrieved by HEC-HMS or HEC-RAS via DSS file names and pathnames. In Figure 6, Paired Data Table 1 in HEC-HMS is established by quoting Storage-Flow paired data mentioned above (Figure 2 Record Number 13).
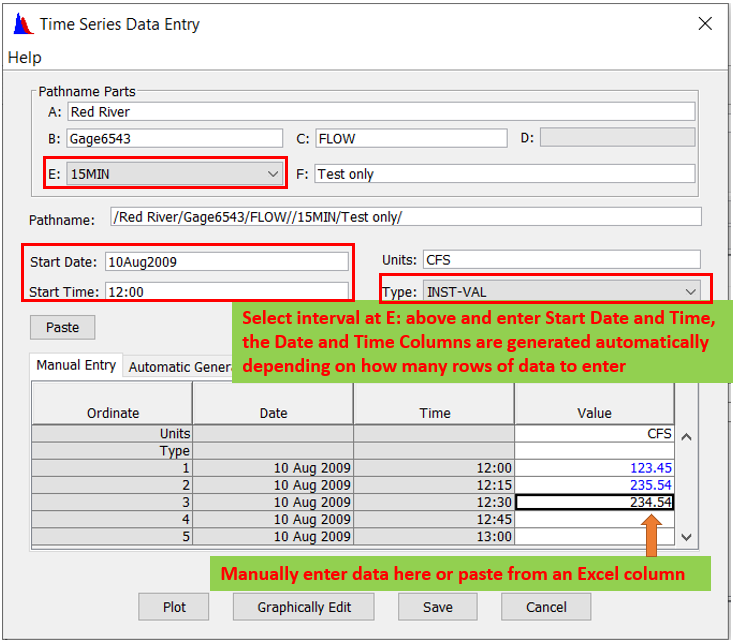
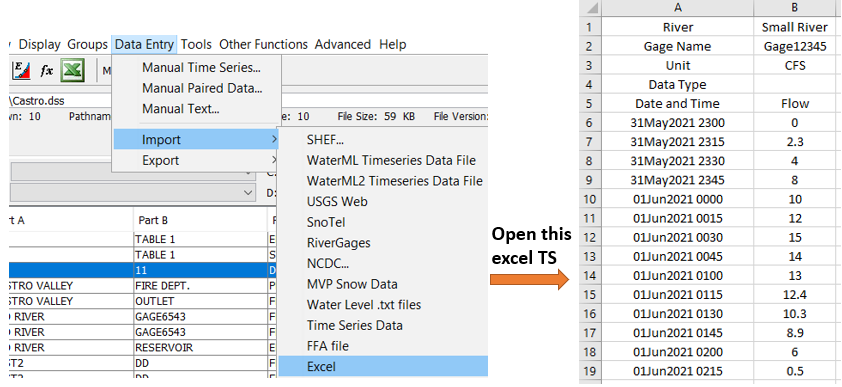
Both time series data and paired data can be entered into a DSS file manually by clicking Data Entry (Figure 8) and then selecting Manual Time Series… (Figure 9) or Manual Paired Data… (Figure 10).
For time series data, it may be more convenient to download or prepare it in Excel and then import to DSS from Excel directly. To import Excel time series data to DSS, click Data Entry and select Import –> Excel (Figure 11) to open the Excel file.
Select the time series data range to be imported (Figure 12) and on the next screen to set up the appropriate properties of the data including Pathname, Units, and Type (Figure 13) . The interval (Part E) and the start date and time are taken from the selected time series data automatically. Flow data can be imported as an instant value (INST-VAL) or an average value over a period (PER-AVER), and DSS interprets these two data types differently as shown in Figure 14.



Leave a Reply